kafkaload
Synopsis
starlake kafkaload [options]
Description
Load data to or offload data from Apache Kafka topics. Supports both producing and consuming messages.
Two modes are available : The batch mode and the streaming mode.
Batch mode
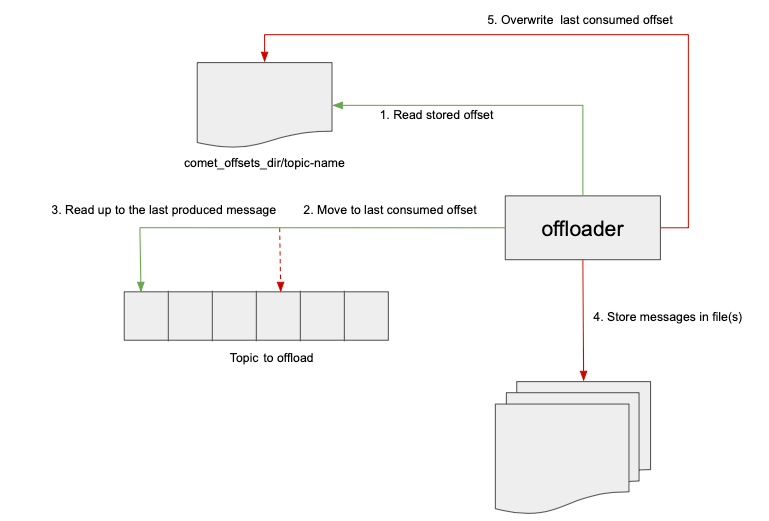
In batch mode, you start the kafka (off)loader regurarly and the last consumed offset
will be stored in the comet_offsets topic config
(see reference-kafka.conf for an example).
When offloading data from kafka to a file, you may ask to coalesce the result to a specific number of files / partitions. If you ask to coalesce to a single partition, the offloader will store the data in the exact filename you provided in the path argument.
The figure below describes the batch offloading process

The figure below describes the batch offloading process with comet-offsets-mode = "FILE"
Streaming mode
In this mode, te program keep running and you the comet_offsets topic is not used. The (off)loader will use a consumer group id you specify in the access options of the topic configuration you are dealing with.
BigQuery support
BigQuery can be used as both a source and a sink format.
Kafka to BigQuery (batch):
starlake kafkaload --config my_topic --write-format bigquery --write-mode Append
--write-options table=project:dataset.table,temporaryGcsBucket=my-bucket
Kafka to BigQuery (streaming):
starlake kafkaload --config my_topic --stream --write-format bigquery
--write-options table=project:dataset.table,temporaryGcsBucket=my-bucket
BigQuery table to Kafka:
starlake kafkaload --format bigquery --path "project:dataset.table"
--options temporaryGcsBucket=my-bucket --write-config my_output_topic
BigQuery query to Kafka:
starlake kafkaload --format bigquery
--options query="SELECT * FROM dataset.table WHERE col > 'value'",temporaryGcsBucket=my-bucket
--write-config my_output_topic
Parameters
| Parameter | Cardinality | Description |
|---|---|---|
--config <value> | Optional | Topic Name declared in reference.conf file |
--connectionRef <value> | Optional | Connection to any specific sink |
--format <value> | Optional | Read/Write format eq : parquet, json, csv, bigquery ... Default to parquet. |
--path <value> | Optional | Source file for load and target file for store |
--options <value> | Optional | Options to pass to Spark Reader |
--write-config <value> | Optional | Topic Name declared in reference.conf file |
--write-path <value> | Optional | Source file for load and target file for store |
--write-mode <value> | Optional | When offload is true, describes how data should be stored on disk. Ignored if offload is false. |
--write-options <value> | Optional | Options to pass to Spark Writer |
--write-format <value> | Optional | Streaming format eq. kafka, console, bigquery ... |
--write-coalesce <value> | Optional | Should we coalesce the resulting dataframe |
--transform <value> | Optional | Any transformation to apply to message before loading / offloading it |
--stream <value> | Optional | Should we use streaming mode ? |
--streaming-trigger <value> | Optional | Once / Continuous / ProcessingTime |
--streaming-trigger-option <value> | Optional | 10 seconds for example. see https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/streaming/Trigger.html#ProcessingTime-java.lang.String- |
--streaming-to-table <value> | Optional | Table name to sink to |
--streaming-partition-by <value> | Optional | List of columns to use for partitioning |
--reportFormat <value> | Optional | Report format: console, json, html |